�������Ƕ��˽����������������ԭ����������֩��������������Ĺ��̣�����ƪ�����������Ƽ�Ϊ��ҷ�����Щ������Ԥ�������棬ϣ���Դ������������

����������ȡ����
����֩������
������������֩����Է�Ϊ��Ȩ��֩�룬��Ȩ��֩�룬��Ȩ֩�룬��ҳ֩�룬��ҳ����֩�룬ͼƬ�ռ�֩�룬ģ����ʵ���������������(��js)
��������
������¼��=��¼����/��ȡ����
�������ڽ���web��־��飬������¼��
������¼�ʷdz��ͣ���Ҫ������������������
��������
�������֩��ʶ����
�������ҵ���һ��������һ�����һ�¡����С�cmd��������tracert֩��IP��ַ���磺tracert 123.125.66.123

������ͼ�������ģ�����Ǻ�ɫ��֣����ǰٶ�֩���ˣ������ģ�����αװ�ġ�
��������һ�ַ�����ͨ��DNS����������ʼ��-�����С�-��cmd��-������nslookup IP��ַ��-���س�����
����nslookup 123.125.66.123�س�������������
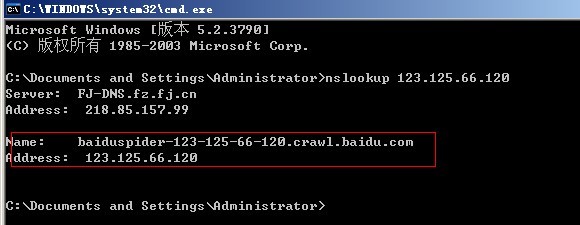
������������ץȡ��ҳ��
�������������б���ҳ���ڷ�������ҳ��ײ���������ҳ�����ר��]���б�������������ʷų������ӡ�
�����������Ŵ�
����������������ȶ�������·ȷ���ȶ����ò������������HTML����ʱռ�ʹ��ٵ��������棬��ȡ������Դ���õ����棻��߷��������ܣ���֤���������ٶȣ�������վҳ�治��Ҫ��js��Ч�ȡ�
���������ύ
����1.sitemap txt�ı���ʽ(�ٶ�)xml��ʽ(�ȸ�)
����֪ͨ��ʽ��������robots.txt�У����Ӵ����֪sitemap����վλ�ã�����ͨ���ٶ�վ����̨���ύsitemap���ٶ�վ������һ�����ύ10��sitemap��
����sitemapҪ���ȳ���5������ļ���С���ij���10mb��������404��
����2.�����ύ
����xenuɨ�輰ʱɾ�������ύ���ٶ�վ����̨�����ύ
����3.��վ�İ���վ����301��ת(�鿴��־ȷ������)վ����̨��վ�����������ɨ��
�����Ƿ���������
����1.robots.txt
����User-agent:*
����Disallow:/
����2.meta
����<meta name="robots"content="noindex,nofollow">
����3.http
����header X-Robots-Tag:noindex
����4.html
����<noindexo��Ҫ�����z�������</noindexprel-"nofollow"
�������ϵľ������DZ��������Ƽ�����˾Ϊ��ҷ������и���Щ������Ԥ����������ϣ���Դ���������������������Ƽ�����˾��IT��ҵרע��ҵ���������Ż�����վ�������ֻ�app������������ʼ����������ҵӪ��������Ϊ��ҵ���������������������û������Ӫ����վ��ͨ������SEO����������վ��������ҵ�İ��裬���dz�Ϊ����Ӫ�����ߣ���ӭ���Ͽͻ�������ѯ��

